








In a production-scale cloud environment, data is scattered across various storage formats and locations, such as RDS databases, DynamoDB tables, time series databases, S3 files, and external systems. While Amazon QuickSight can directly connect to many data sources, it is often not preferred due to design principles, costs, performance, and user experience. Instead, the best practice is to build a centralized data lake with tools to consolidate and transform data for business intelligence tools. But how can you optimize the data pipeline from ingestion to insights to ensure processed data is ready for analysis as quickly as possible?
In this article, we use real-world open data sets on Helsinki region public traffic, imported as DynamoDB tables. We showcase, how we can transform data from the source to a Data Lake in S3, combine the Data Sets in QuickSight to create interesting and actionable insights, and eventually, how we can speed up the Data Pipeline to ensure the insights are always as up-to-date as possible.
Anatomy of a typical Serverless Data Pipeline on AWS
NordHero has implemented data pipelines for various customers on AWS utilizing our Data to Insights Jump Start offering. The solution uses
- AWS Glue Jobs to extract data from their sources, transform the data to be efficiently utilized with BI tools, and load the data in Parquet or ORC format to a data lake based on Amazon S3
- AWS Glue Crawlers to determine the data lake schemas and to store the schemas in AWS Glue Data Catalog
- Amazon Athena to provide a scalable and super-fast SQL interface to the data stored in the S3 data lake
- AWS QuickSight to analyze the data, build actionable insights on the data, and deliver the insights to business users
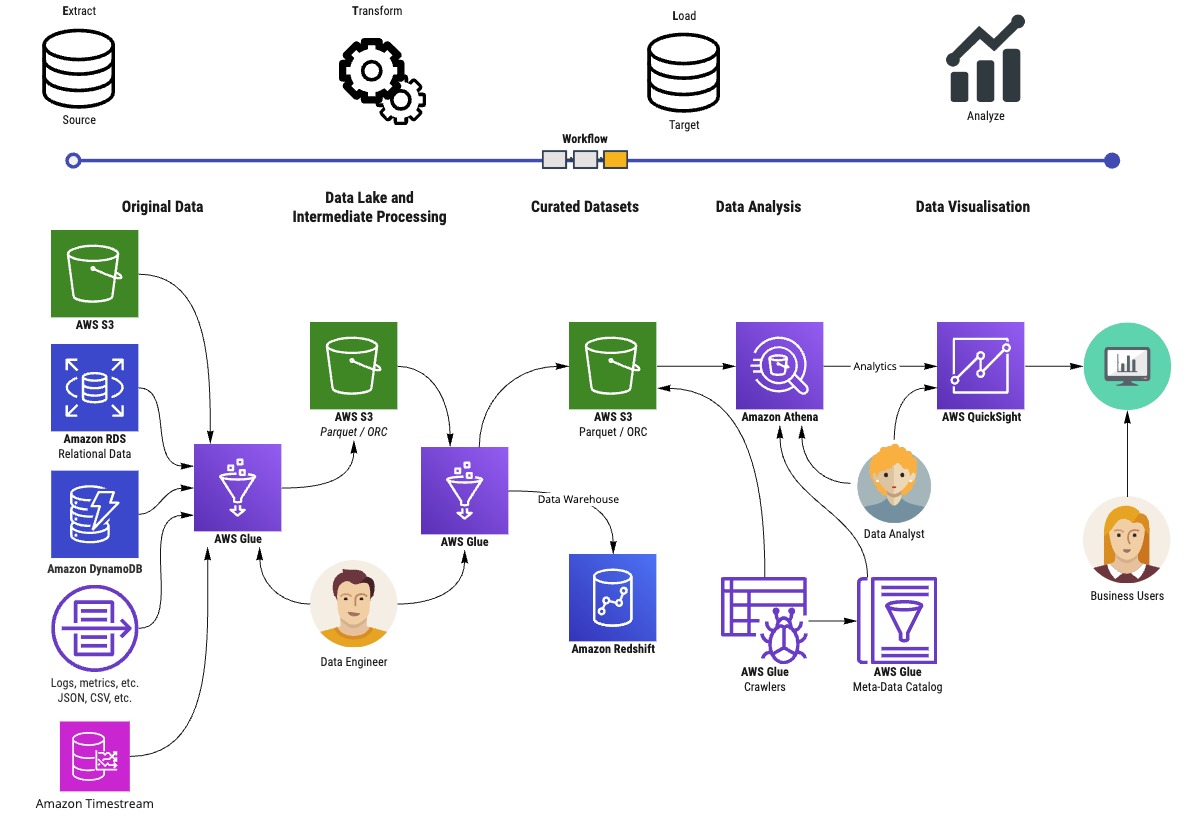
An example of Serverless Data Pipeline on AWS
AWS Glue is an AWS-managed service, meaning that AWS manages the needed compute instances, their software, and the scaling of the resources. You only pay for your data’s processing time. You can create and run several AWS Glue jobs to extract, transform, and load (ETL) data from various data sources into the data lake and build different curated datasets in the data lake for various data consumption needs.
Amazon S3 is an ideal service to be used as the storage foundation for a data lake, providing several benefits:
- Scalability and Elasticity: Amazon S3 can scale massively to store virtually unlimited amounts of data, without the need for provisioning or managing storage infrastructure.
- Data Lake Architecture: S3 enables a decoupled storage and compute architecture, allowing you to store data in its raw form and use various analytics services and tools to process and analyze the data without being tied to a specific compute engine. S3 integrates seamlessly with various AWS analytics services like Amazon Athena, AWS Glue, Amazon EMR, Amazon QuickSight, and AWS Lake Formation, enabling you to build end-to-end data processing and analytics pipelines.
- Cost-Effective: Amazon S3 offers a cost-effective storage solution, with pricing based on the amount of data stored and accessed. You can also leverage different storage classes (e.g., S3 Glacier) for cost optimization based on data access patterns.
- Data Durability and Availability: Amazon S3 is designed for 99.999999999% durability and 99.99% availability, ensuring your data is safe and accessible when needed.
- Data Lake Security and Compliance: Amazon S3 provides robust security features, including access control, encryption at rest and in transit, and integration with AWS Identity and Access Management (IAM) for granular permissions management.
- Data Sharing and Collaboration: With Amazon S3, you can easily share data across teams, projects, or even with external parties, enabling collaboration and data monetization opportunities.
- Centralized Data Repository: A data lake on Amazon S3 serves as a centralized repository for all your structured, semi-structured, and unstructured data, breaking down data silos and enabling data democratization within your organization.
Here’s an example AWS Glue Job script, written in Python, that extracts passenger data from a DynamoDB table named hsl-passengers, transforms the column names from uppercase to lowercase, casts passenger_count field from String to Integer type, and lastly writes the transformed data in an S3 bucket in Parquet format.
import sys
from datetime import datetime, date, timedelta
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.dataframe import DataFrame
from pyspark.sql.types import IntegerType
from pyspark.sql.functions import col
SPARK_CONTEXT = SparkContext.getOrCreate()
GLUE_CONTEXT = GlueContext(SPARK_CONTEXT)
spark = GLUE_CONTEXT.spark_session
logger = GLUE_CONTEXT.get_logger()
def read_dynamo_db(tablename: str):
"""Reads DynamoDB table into a DynamicFrame"""
dyf = GLUE_CONTEXT.create_dynamic_frame.from_options(
connection_type="dynamodb",
connection_options={
"dynamodb.input.tableName": f"{tablename}",
"dynamodb.throughput.read.percent": "0.5",
"dynamodb.splits": "1",
},
)
return dyf
def write_log(message: str):
"""Writes log to multiple outputs"""
logger.warn(message)
print(message)
def write_to_s3(s3_output_base_path: str, name: str, df: DataFrame):
"""Writes data to specific folder in S3"""
path = f"{s3_output_base_path}/{name}"
if not ("processed" in path):
raise Exception(
"Output folder must contain path element 'processed' to be valid"
)
write_log(f"Writing output to {path}")
df.write.mode("overwrite").format("parquet").partitionBy("object_id").save(path)
def main():
# @params: [JOB_NAME]
args = getResolvedOptions(
sys.argv,
["JOB_NAME", "s3_output_path"],
)
job = Job(GLUE_CONTEXT)
job.init(args["JOB_NAME"], args)
# Let's only overwrite partitions that have changed, even though we store all data
spark.conf.set("spark.sql.sources.partitionOverwriteMode", "dynamic")
s3_output_path = args["s3_output_path"]
write_log(f"Parameter 's3_output_path': {s3_output_path}")
# Reading data from DynamoDb
passengers_raw = read_dynamo_db("hsl-passengers").toDF()
passengers = (
passengers_raw.withColumnRenamed("OBJECTID", "object_id")
.withColumnRenamed("SHORTID", "short_id")
.withColumnRenamed("STOPNAME", "stop_name")
.withColumn("passenger_count", col("PASSENGERCOUNT").cast(IntegerType()))
.drop("PASSENGERCOUNT")
)
write_to_s3(s3_output_path, "passengers-data", passengers)
job.commit()
if __name__ == "__main__":
main()
When you trigger the AWS Glue Job, AWS Glue fires up the needed Apache Spark compute instances, manages the parallel job execution between cluster nodes, and ramps down the compute services after the job execution has finished.
Optimizing the data delivery to the data lake with AWS Glue
You need to consider several things when optimizing the ETL process with AWS Glue, but eventually, it comes down to two criteria. The primary criterion is Time. The data lake is never 100% up-to-date with the source data. So the key question is, how often should the data be updated? The secondary criterion is always Money. After setting the Time criterion, how can the costs of the ETL process be optimized?
To beat the criteria, you need to plan your data pipeline well. Here are a few spices to compete against the clock:
- Scale cluster capacity: Adjust the number of Data Processing Units (DPUs) and worker types based on your workload requirements. AWS Glue allows you to scale resources up or down to match the demands of your ETL jobs.
- Use the latest AWS Glue version: AWS regularly releases new versions of AWS Glue with performance improvements and new features. Upgrade to the latest version to take advantage of these enhancements.
- Reduce data scan: Minimize the amount of data your jobs scan by using techniques like partitioning, caching, and filtering data early in the ETL process.
- Parallelize tasks: Divide your ETL tasks into smaller parts and process them concurrently to improve throughput. AWS Glue supports parallelization through features like repartitioning and coalesce operations.
- Minimize planning overhead: Reduce the time spent on planning by optimizing your AWS Glue Data Catalog, using the correct data types, and avoiding unnecessary schema changes.
- Optimize shuffles: Minimize the amount of data shuffled between tasks, as shuffles can be resource-intensive. Use techniques like repartitioning and coalescing to reduce shuffles.
- Optimize user-defined functions (UDFs): If you’re using UDFs, ensure they are efficient and optimize their execution using vectorization and caching.
- Use AWS Glue Auto Scaling: Enable AWS Glue Auto Scaling to adjust the number of workers based on your workload automatically, ensuring efficient resource utilization.
- Monitor and tune: Use AWS Glue’s monitoring capabilities, such as the Spark UI and CloudWatch metrics, to identify bottlenecks and tune your jobs accordingly.
- Leverage AWS Glue Workflow: Use AWS Glue Workflow to orchestrate and manage your ETL pipelines, ensuring efficient execution and resource utilization.
- Optimize data formats: Use columnar data formats like Parquet or ORC, which are optimized for analytical workloads and can improve query performance.
- Leverage AWS Glue Data Catalog: Use the AWS Glue Data Catalog to store and manage your data schemas, which can improve planning and reduce overhead.
- Optimize data compression: Use appropriate compression techniques to reduce the amount of data transferred and stored, improving performance and reducing costs.
- Avoid processing the same data multiple times: Use AWS Glue Job bookmarks to track the data already processed by the ETL job, and update only the changed partitions when loading data to the data lake.
Here’s an example of AWS Glue Workflow. The workflow processes Helsinki Region Transport (HSL) open data on passenger amounts and public transport stops and shifts. The workflow has a trigger named hsl-data-glue-workflow-trigger that is configured to start once per hour. The trigger will fire up five parallel AWS Glue Jobs to process data related to shifts, passengers, stoptypes, network and stops. When all these Jobs end up in the SUCCESS state, the hsl-data-glue-crawler-trigger is triggered to start an AWS Glue Crawler to update the data schemas in the AWS Glue Data Catalog.
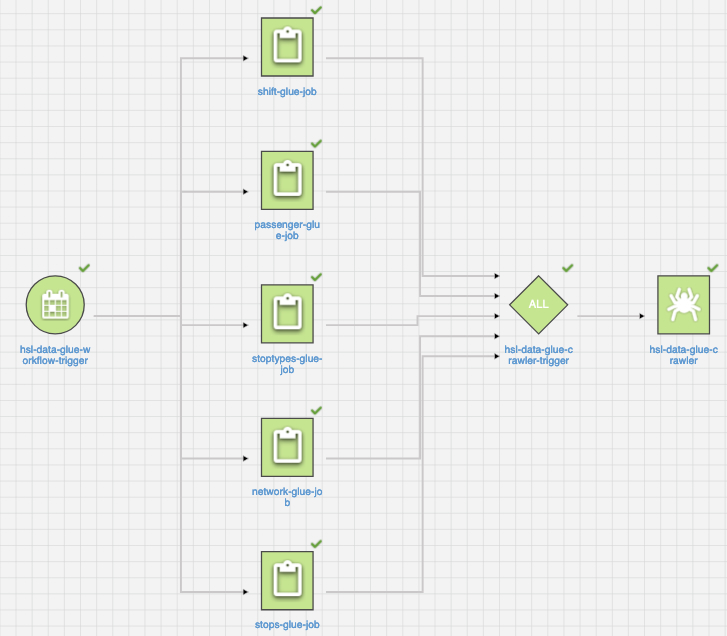
An example of AWS Glue Workflow that processes open HSL transport data
AWS Glue Workflows support three types of start triggers:
- Schedule: The workflow is started according to a defined schedule (e.g., daily, weekly, monthly, or a custom cron expression).
- On-demand: The workflow is started manually from the AWS Glue console, API, or AWS CLI.
- EventBridge event: The workflow starts with a single Amazon EventBridge event or a batch of Amazon EventBridge events.
Optimizing the data insights experience with Amazon QuickSight
From a data consumption perspective, the key criterion is that the data be up-to-date and instantly available. If there’s lots of data in the data lake, updating an analysis or dashboard view in Amazon QuickSight might take even tens of seconds. That will make the business analytics experience very poor and generate lots of costs.
Amazon QuickSight has solved this issue with a lightning-fast in-memory caching solution called SPICE (Super-fast, Parallel, In-memory Calculation Engine). When configuring QuickSight DataSets, you have the option to either query the underlying data directly or utilize SPICE. QuickSight comes with a 10 GB SPICE allocation per QuickSight Author license, and additional SPICE capacity can be purchased with GB/month pricing.
When using SPICE, the underlying data from the data sources, such as a data lake, is loaded into SPICE. QuickSight Analyses and Dashboards utilize only the version of data available in SPICE. SPICE can be refreshed
- manually
- by a preconfigured schedule
- through QuickSight API
The SPICE refresh timing becomes an issue when targeting to have as recent data available in QuickSight as possible. Consider a situation where the Glue Workflow, containing multiple ETL jobs, runs once per hour and updates several datasets in the S3 data lake. In our imaginary example, the workflow process typically lasts 20 minutes. Still, depending on the amount of changed data in the data sources since the last run and the current utilization level of the AWS-managed Glue hardware, the Workflow run can take between 14 and 40 minutes.
In addition, the QuickSight SPICE refresh process runs on AWS-managed computing resources, and in our case, refreshing one QuickSight DataSet might take 2-8 minutes.
And in a typical production-scale QuickSight environment, the order of DataSet refreshes matter. There are “simple” DataSets that are not dependent on any other DataSet and then there combined DataSets that utilize simple DataSets. Before starting to refresh one DataSet in QuickSight, we need to be sure that all underlying DataSets our DataSet is dependent on have first been refreshed.
Here’s an example of a combined DataSet in QuickSight. All datasets available in data lake have first been brought to QuickSight, and now the passengers data is first joined with stops data while passenger amounts are counted per stop. Then stops data is joined with stoptypes data (whether the stop is a glass shelter, steel shelter, post,…), network data (is it a bus stop, subway stop, tram stop,…) and shifts data (number of public transport shifts between different stops).
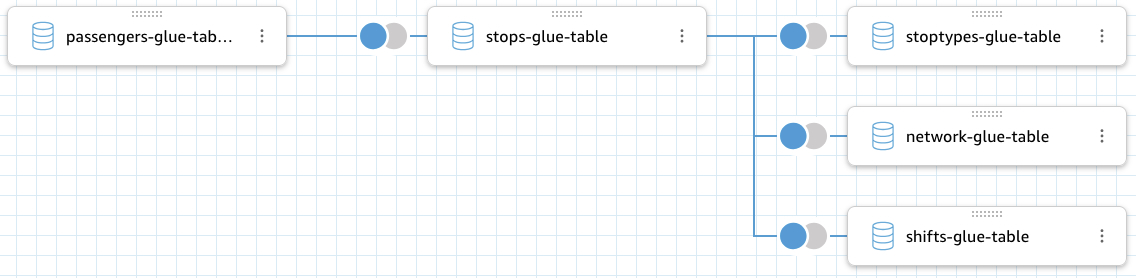
An example of a combined DataSet in QuickSight
Optimizing the whole data pipeline from ingestion to insights with event triggering and AWS Step Functions
So how can we manage this all automatically and with optimal timing? To solve the issues, we need to
- use AWS Glue Workflow to automate and order the Jobs and Crawlers within the Glue ETL process
- Refresh the QuickSight DataSets into SPICE immediately after Glue Workflow has finished its execution
- Refresh the QuickSight DataSets in the correct order so that the “simple” DataSets get updated first and combined DataSets right after the simple ones
Luckily we can achieve the latter two by utilizing AWS StepFunctions and CloudWatch Event Triggering!
Triggering a Step Function when Glue Workflow has finished
AWS Glue Crawlers create CloudWatch Events on their lifecycle changes, and we can trigger an AWS Step Function State Machine execution when the last Crawler in our Glue Workflow sends a Succeeded event. Here’s a CDK/TypeScript snippet on creating the event rule to watch for Glue Crawler state change events and to start the Step Function execution:
// Event rule to trigger the Step Function
new events.CfnRule(this, "CrawlerSucceededRule", {
description: "Glue crawler succeeded",
roleArn: smTriggerRole.roleArn,
name: `statemachine-trigger-rule`,
eventPattern: {
source: ["aws.glue"],
"detail-type": ["Glue Crawler State Change"],
detail: {
state: ["Succeeded"],
crawlerName: [{ "equals-ignore-case": `hsl-data-glue-crawler` }],
},
},
targets: [
{
arn: cfnStateMachine.attrArn,
id: cfnStateMachine.attrName,
roleArn: smTriggerRole.roleArn,
},
],
});
Refreshing QuickSight DataSets with AWS Step Functions State Machine
The AWS Step Functions have inbuilt integrations with loads of different AWS services, including AWS QuickSight. Therefore, it is straightforward to build a State Machine that starts refreshing the QuickSight DataSet SPICE - the process is called DataSet Ingestion. The following image shows an AWS Step Functions State Machine that processes QuickSight DataSet Ingestions in two phases - in the first phase, it parallelly ingests data on five QuickSight DataSets: network, stops, passengers, shifts and stoptypes. When all those ingestions have been successfully finished, the State Machine continues to ingest the second set of QuickSight DataSets, which in this example contains only one DataSet: passengers-and-stops.
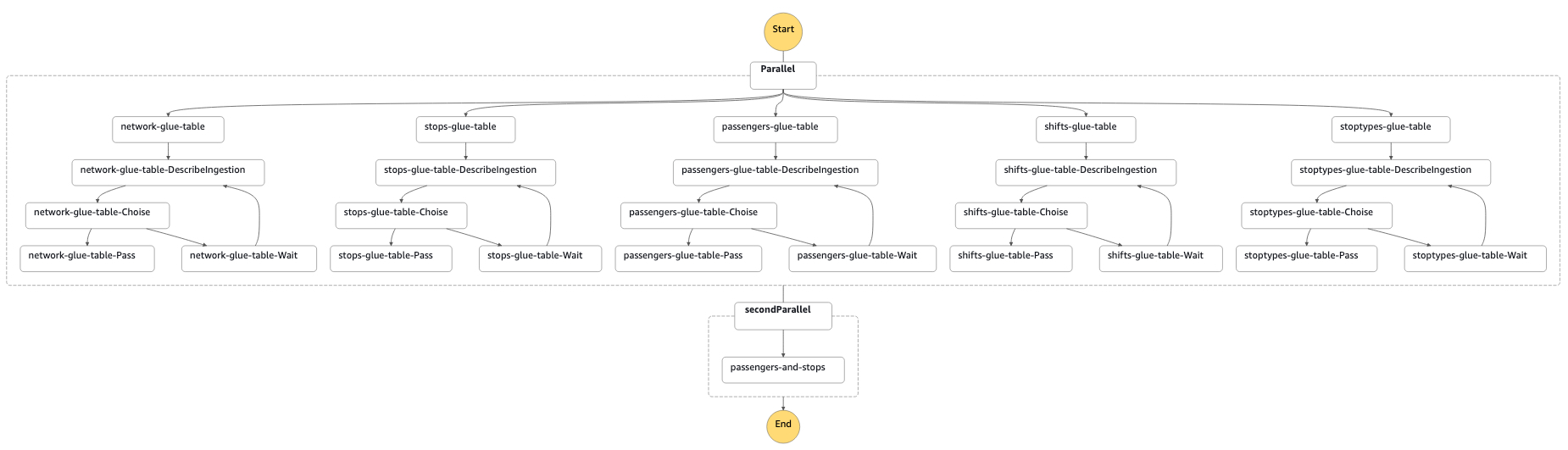
An example of a Step Function that ingests QuickSight DataSet refreshes in two phases
For each QuickSight DataSet, the State Machine
- Starts the Ingestion process with CreateIngestion call and saves the IngestionId value of the started Ingestion process
- Checks the Ingestion status with DescribeIngestion call
- If IngestionStatus is COMPLETED, CANCELLED or FAILED, it will pass the phase
- Otherwise, it will wait for 20 seconds and check the Ingestion status again
Summing it up
As an end result, we now have a data pipeline that is triggered automatically by a predefined schedule, or with EventBridge event, and that starts ingesting QuickSight DataSets in correct order and as quickly as underlying data is updated. And now we can enjoy the actionable, up-to-date insights:
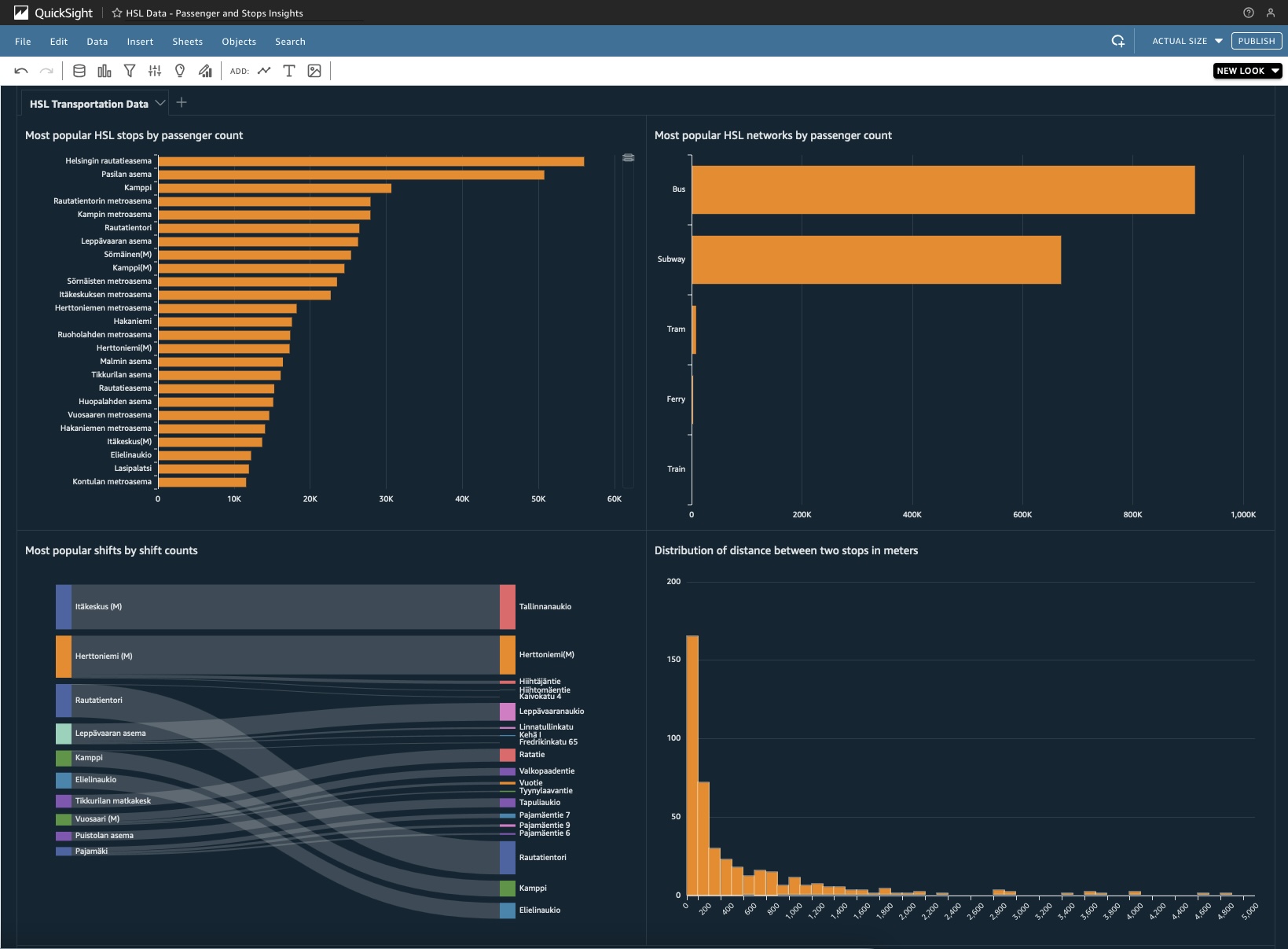
An example of AWS QuickSight Analysis that utilizes combined QuickSight DataSets
In this article, we reviewed the components of AWS’s serverless data lake solution and explored ways to optimize its performance and user experience. Lastly, we learned how to automate the whole process from data ingestion to data insights with AWS Step Functions and AWS Glue Crawler Event Triggering.
We hope you enjoyed the journey. If you would like to set up a Serverless Data Pipeline and Data Lake on AWS, we are here to help. Just contact us or book a meeting with us!
The examples in this article were build using data adapted from Helsinki Region Transport’s (HSL) public data on transport stations, shifts and passengers. The original data is available on Helsinki Region Infoshare site.